

Java并发性和多线程介绍
多线程技术,使得在一个程序内部能拥有多个线程并行执行。一个线程的执行可以被认为是一个CPU在执行该程序。当一个程序运行在多线程下,就好像有多个CPU在同时执行该程序。
如果一个线程在读一个内存时,另一个线程正向该内存进行写操作,那进行读操作的那个线程将获得什么结果呢?是写操作之前旧的值?还是写操作成功之后的新值?或是一半新一半旧的值?或者,如果是两个线程同时写同一个内存,在操作完成后将会是什么结果呢?是第一个线程写入的值?还是第二个线程写入的值?还是两个线程写入的一个混合值?因此如没有合适的预防措施,任何结果都是可能的。而且这种行为的发生甚至不能预测,所以结果也是不确定性的。
Java是最先支持多线程的开发的语言之一,Java从一开始就支持了多线程能力
多线程的优点
- 资源利用率更好
- 程序设计在某些情况下更简单
- 程序响应更快
资源利用率更好
CPU能在等待IO的时候做一些其它事情,这个也不一定就是磁盘IO,它也可以是网络IO,或者用户输入,通常,网络和磁盘的IO要比CPU和内存的IO慢得多
程序设计更简单
在单线程应用程序中,如果你想编写程序手动处理多个文件的读取和处理的顺序,你必须记录每个文件读取和处理的状态。相反,你可以启动两个线程,每个线程处理一个文件的读取和操作。线程会在等待磁盘读取文件的过程中被阻塞。在等待的时候,其他的线程能够使用CPU去处理已经读取完的文件。其结果就是,磁盘总是在繁忙地读取不同的文件到内存中。这会带来磁盘和CPU利用率的提升。而且每个线程只需要记录一个文件,因此这种方式也很容易编程实现。
程序响应更快
将一个单线程应用程序变成多线程应用程序的另一个常见的目的是实现一个响应更快的应用程序。设想一个服务器应用,它在某一个端口监听进来的请求。当一个请求到来时,它去处理这个请求,然后再返回去监听。
服务器的流程如下所述:
1 | while(server is active){ |
2 | listen for request |
3 | process request |
4 | } |
如果一个请求需要占用大量的时间来处理,在这段时间内新的客户端就无法发送请求给服务端。只有服务器在监听的时候,请求才能被接收。另一种设计是,监听线程把请求传递给工作者线程(worker thread),然后立刻返回去监听。而工作者线程则能够处理这个请求并发送一个回复给客户端。这种设计如下所述:
1 | while(server is active){ |
2 | listen for request |
3 | hand request to worker thread |
4 | } |
这种方式,服务端线程迅速地返回去监听。因此,更多的客户端能够发送请求给服务端。这个服务也变得响应更快。
桌面应用也是同样如此。如果你点击一个按钮开始运行一个耗时的任务,这个线程既要执行任务又要更新窗口和按钮,那么在任务执行的过程中,这个应用程序看起来好像没有反应一样。相反,任务可以传递给工作者线程(word thread)。当工作者线程在繁忙地处理任务的时候,窗口线程可以自由地响应其他用户的请求。当工作者线程完成任务的时候,它发送信号给窗口线程。窗口线程便可以更新应用程序窗口,并显示任务的结果。对用户而言,这种具有工作者线程设计的程序显得响应速度更快。
多线程的代价
从一个单线程的应用到一个多线程的应用并不仅仅带来好处,它也会有一些代价。不要仅仅为了使用多线程而使用多线程,而应该明确在使用多线程的好处比所付出的代价大的时候,才使用多线程。如果有疑问,可以尝试测量一下应用程序的性能和响应能力,而不只是猜测
设计更复杂
虽然有一些多线程应用程序比单线程的更简单,但其它的一般更复杂,在多线程访问共享数据的时候,这部分代码要特别注意,线程之间交互非常复杂,不正确的线程同步产生的错误非常难以被发现,并且重现以修复
上下文切换的开销
当CPU从执行一个线程切换到另一个线程的时候,它需要存储当前线程的本地的数据,程序指针等,然后载入另一个线程的本地数据,程序指针等,最后才开始执行。这种切换称为 “上下文切换” ,context switch。上下文切换并不廉价,如果没有必要,应该减少上下文切换的发生
增加资源消耗
线程在运行的时候需要从计算机里面的到一些资源,除了CPU,线程还需要一些内存来维持它本地的栈,它也需要占用操作系统中一些资源来管理线程。我们可以尝试编写一个程序,让他创建100个线程,这些线程什么也不做,只是在等待,然后看看这个程序在运行的时候占用了多少内存。
锁带来的性能影响
什么时候该用锁,什么时候不用,往往要决定好,锁的粒度也很重要,只对必要的数据枷锁
并发编程模型
并发系统可以采用多种并发编程模型来实现。并发模型制定了系统中的线程如何通过协作来完成分配给它们的作业。不同的并发模型采用不同的方式拆分作业,同时线程间的协作和交互方式也不同。这部分将会介绍目前比较流行的几种并发编程模型。
本文所描述的多种并发模型类似于分布式系统中使用的很多体系结构。在并发系统中线程间可以相互通信,在分布式系统中,进程可以相互通信(进程可能在不同的机器中)。线程和进程间具有很多相似的特性,这也就是为什么很多并发模型通常类似于各种分布式系统架构(当然,分布式系统在处理网络失效、远程主机或进程宕掉等方面还面临额外的挑战)
并发模型一:并行工作者模型
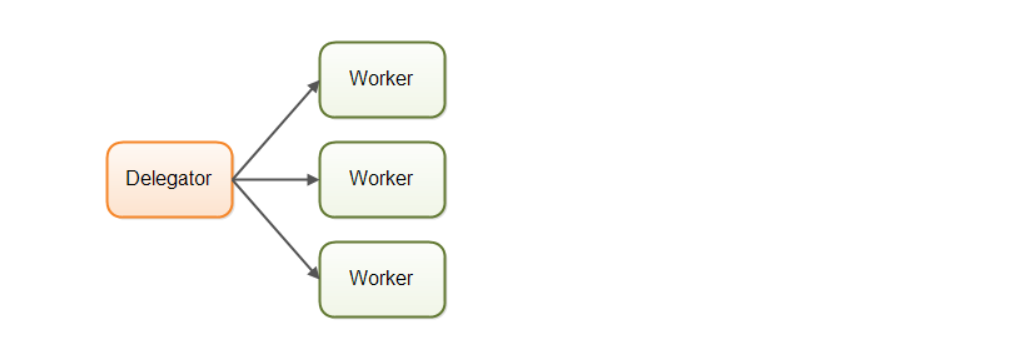
在并行工作者模型中,委派者(Delegator)将传入的作业分配给不同的工作者,每个工作者完成整个任务,工作者们并行地运行在不同的线程上,甚至可能在不同的CPU上
比如在某个汽车厂里实现了并行工作者模型,每台车都会由一个工人来生产,工人们拿到汽车的生产规格,并且从头到尾负责所有工作。在Java应用系统中,并性工作者模型是最常见的并发模型(即使正在改变)。java,util.concurrent包中的许多工具都是设计用于这个模型的
并发工作模型的优点
并行工作者模型的优点是它很容易理解和操作,你只需要添加更多的工作者来提高系统的并行度
并行工作者模型的缺点
1.共享状态可能会很复杂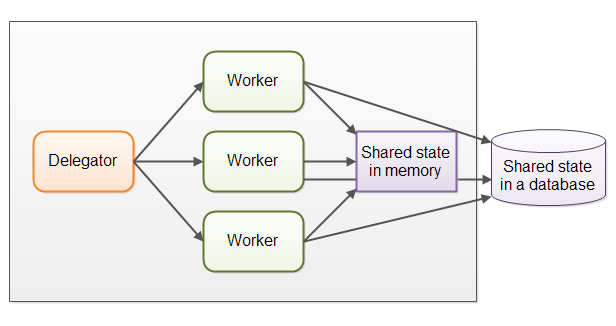
一旦共享状态潜入到并行工作者模型中,将会使情况变得复杂起来。线程需要以某种方式存取共享数据,以确保某个线程的修改能够对其他线程可见(数据修改需要同步到主存中,不仅仅将数据保存在执行这个线程的CPU的缓存中)。线程需要避免竟态,死锁以及很多其他共享状态的并发性问题。
此外,再等待访问共享数据时,线程之间的等待将会丢失部分并行性。许多并发数据结构是阻塞的,意味着在任何时候,只有一个或者很少的线程能够访问,这样会导致在这些共享数据结构上出现竞争状态。在执行需要访问共享数据结构部分的代码时,高竞争态基本上会导致执行时出现一定程序的串行化(TODO)。
现在的非阻塞并发算法也许可以降低竞争并提升性能,但是非阻塞算法的实现比较困难。
可持久化的数据结构是另一种选择
在修改的时候,可持久化的数据结构总是保护它的前一个版本不受影响。因此,如果多个线程指向同一个可持久化的数据结构,并且在其中一个线程做了修改,进行修改的线程会获得一个指向新结构的引用。所有其他线程保持对旧结构的引用(注:这里的可持久化数据不是指持久化存储,而是一种数据结构,比如Java中的String类,以及CopyOnWriteArrayList类,具体可参考可持久化数据)
无状态的工作者
共享状态能够被系统中其它线程修改,所以工作者在每次需要的时候必须重读状态,以确保每次都能访问到最新的副本(Dan:这个与前面的可持久化数据不冲突,代表了不同的处理情景).工作者无法在内部保存这个状态(但是可以重读)称为无状态的。
每次都需要重读的数据,将会导致速度变慢,特别是状态保存在外部数据库的时候
并发模型二:流水线模式
我们之所以选择这个名字,是与并行工作者想比较而言,根据平台的不同,也被称为如反应器系统、或事件驱动系统,下面是一个流水线并发模型的模型图: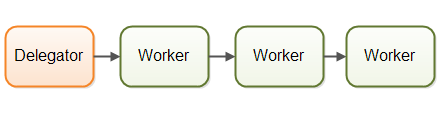
Defination:
类似于工厂生产线上的工人那样组织工作者,每个工作者只负责作业中的部分工作。当完成了自己的这部分工作时,工作者会将作业转发给下一个工作者,每个工作者在自己的线程中运行,并且不会和其它工作者共享状态,有时也称为无共享并行模型。
通常用非阻塞的IO来设计流水线并发模型的系统。非阻塞IO意味着,一旦某个工作者开始一个IO操作的时候(比如读取文件或从网络连接中读取数据),这个工作者不会一直等待IO操作的结束。IO操作速度很慢,所以等待IO操作结束很浪费CPU时间。此时CPU可以做一些其它事情。当IO操作结束的时候,IO结果(比如读出的数据或者数据写完的状态)被传递给下一个工作者。
有了非阻塞IO,就可以使用IO操作确定工作者之间的边界。工作者会尽可能多运行直到遇到并启动一个IO操作。然后交出作业的控制权。当IO操作完成的时候,在流水线上的下一个工作者继续进行操作,直到它也遇到并启动一个IO操作。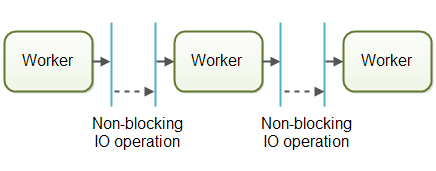
….. To Be Continue…….
如何创建并运行Java线程
Java线程类也是一个Object类,它的实例都继承自java.lang.Thread或其子类
1 | public Thread implements Runnable{ |
2 | ... |
3 | private final Object lock = new Object(); |
4 | .... |
5 | private Runnable target; |
6 | private ThreadGroup group; |
7 | .... |
8 | ThreadLocal.ThreadLocalMap threadLocals = null; |
9 | ... |
10 | private long stackSize; |
11 | ... |
12 | private long id; |
13 | ... |
14 | |
15 | |
16 | public sychronized void start(){ |
17 | if(started) |
18 | throw new IllegalThreadStateException(); |
19 | group.add(this); |
20 | |
21 | started = false; |
22 | try { |
23 | nativeCreate(this, stackSize, daemon); |
24 | started = true; |
25 | } finally { |
26 | try { |
27 | if (!started) { |
28 | group.threadStartFailed(this); |
29 | } |
30 | } catch (Throwable ignore) { |
31 | /* do nothing. If start0 threw a Throwable then |
32 | it will be passed up the call stack */ |
33 | } |
34 | } |
35 | } |
36 | |
37 | |
38 | |
39 | public void run(){ |
40 | if(target!=null){ |
41 | target.run(); |
42 | } |
43 | } |
44 | |
45 | } |
创建Thread的子类
1 | public class MyThread extends Thread{ |
2 | |
3 | public void run(){ |
4 | System.out,println("MyThread running"); |
5 | } |
6 | } |
7 | |
8 | MyThread mThread = new MyThread(); |
9 | mThread.start(); |
一旦线程启动后start就会立即返回(返回并不代表会返回一个返回值,而是回到当前线程的执行路径上来,继续下一条语句的执行),而不会等到run方法执行完毕才返回,就好像run方法是在另外一个cpu上执行一样。
你也可以通过创建Thread的匿名子类的方式,这里就不写具体的Sample了。
实现 Runnable 接口
1 | public class Runnable implements Runnable{ |
2 | public void run(){ |
3 | System.out.println("MyRunnable running"); |
4 | } |
5 | } |
6 | |
7 | Thread thread = new Thread(new MyRunnable()); |
8 | thread.start(); |
在创建线程的时候,你也可以给它取一个名字,有助于区分不同的线程和分析
创建子类还是实现Runnable接口?
对于这两种方式哪种好并没有一个确定的答案,它们都能满足要求。就我个人意见,我更倾向于实现Runnable接口这种方法。因为线程池可以有效的管理实现了Runnable接口的线程,如果线程池满了,新的线程就会排队等候执行,直到线程池空闲出来为止。而如果线程是通过实现Thread子类实现的,这将会复杂一些。
有时我们要同时融合实现Runnable接口和Thread子类两种方式。例如,实现了Thread子类的实例可以执行多个实现了Runnable接口的线程。一个典型的应用就是线程池[TODO]。
常见错误:调用run方法而非start方法
创建并运行一个线程所犯的常见错误是调用线程的run()方法而非start()方法,如下所示:
1 | Thread newThread = new Thread(MyRunnable()); |
2 | newThread.run(); //should be start(); |
起初你并不会感觉到有什么不妥,因为run()方法的确如你所愿的被调用了。但是,事实上,run()方法并非是由刚创建的新线程所执行的,而是被创建新线程的当前线程所执行了。也就是被执行上面两行代码的线程所执行的。想要让创建的新线程执行run()方法,必须调用新线程的start方法。
Sample:
1 | public class ThreadExample { |
2 | public static void main(String[] args){ |
3 | System.out.println(Thread.currentThread().getName()); |
4 | for(int i=0; i<10; i++){ |
5 | new Thread("" + i){ |
6 | public void run(){ |
7 | System.out.println("Thread: " + getName() + "running"); |
8 | } |
9 | }.start(); |
10 | } |
11 | } |
12 | } |
需要注意的是,尽管启动线程的顺序是有序的,但是执行的顺序并非是有序的。也就是说,1号线程并不一定是第一个将自己名字输出到控制台的线程。这是因为线程是并行执行而非顺序的。Jvm和操作系统一起决定了线程的执行顺序,他和线程的启动顺序并非一定是一致的。
竟态条件与临界区
在同一个程序中运行多个线程本身不会导致问题,问题在于多个线程访问了相同的资源。如同一内存区(变量,数组或者对象)、系统(数据库、web service等) 或文件。实际上,这些问题只有在一或者多个线程向这些资源做了写操作时才有可能发生(一个写也有可能哈,因为你读取前和读取后实际上状态发生改变了,此时的处理可能就是错误的),**只要资源没有发生变化,多个线程读取相同的资源就是安全的。
多线程同傻瓜hi执行下面的代码可能会出错:
1 | public class Counter{ |
2 | protected long count = 0; |
3 | public void add(long value){ |
4 | this.count = this.count + value; |
5 | } |
6 | } |
判断一个操作是否是线程安全的,往往要从JVM的角度区理解,因为有些语句可能被拆分为多条指令
1 | 从内存获取 this.count 的值放到寄存器 |
2 | 将寄存器中的值增加value |
3 | 将寄存器中的值写回内存 |
这段代码可能会产生很多意外的结果,这里我们随便分析一种情况,线程A和线程B同时执行Counter对象的add方法
1 | this.count = 0; |
2 | A: 读取 this.count 到一个寄存器 (0) |
3 | B: 读取 this.count 到一个寄存器 (0) |
4 | B: 将寄存器的值加2 |
5 | B: 回写寄存器值(2)到内存. this.count 现在等于 2 |
6 | A: 将寄存器的值加3 |
7 | A: 回写寄存器值(3)到内存. this.count 现在等于 3 |
可以看到,最后的count的值等于3,可不是5哦
Defination:
当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞争条件。导致竞争条件发生的代码称为临界区。
在临界区中使用适当的同步就可以避免竞态条件
线程安全与共享资源
允许被多个线程同时执行的代码称为线程安全的代码。线程安全的代码不包含竞态条件。
当多个线程同时更新共享资源的时候会引发竞态条件,因此,了解Java线程执行时共享了什么资源很重要。
局部变量
局部变量包含几种情况,包含基本类型的局部变量,以及局部的对象引用 变量。这两种情况需要区分对待
局部基本类型变量
局部变量存储在线程私有区:线程自己的栈中。也就是说,局部基本类型变量永远不会被多个线程共享,所以说,局部基本类型变量是线程安全的。下面举个例子:
1 | public void someMethod(){ |
2 | long threadSafeInt = 0; |
3 | threadSafeInt++; |
4 | } |
我们可以实验下,分别用线程A和线程B去操作,最后分别打印 threadSafeInt 的数值
1 | public class ThreadSafetyTest { |
2 | |
3 | public static void main(String[] args){ |
4 | new Thread(new Runnable() { |
5 | |
6 | public void run() { |
7 | new ThreadSafetyTest().add(); |
8 | } |
9 | },"Thread_A").start(); |
10 | |
11 | new Thread(new Runnable() { |
12 | |
13 | public void run() { |
14 | new ThreadSafetyTest().add(); |
15 | } |
16 | },"Thread_B").start(); |
17 | } |
18 | |
19 | |
20 | public void add(){ |
21 | int i = 0; |
22 | for(i=0;i<100;i++){ |
23 | |
24 | } |
25 | System.out.println(Thread.currentThread().getName()+" : "+ i); |
26 | } |
27 | } |
28 | --------------Terminal--------- |
29 | Thread_A : 100 |
30 | Thread_B : 100 |
局部对象引用变量
对象的局部引用和基础类型的局部变量不太一致,尽管引用本身并没有被共享,但引用所指的对象并没有被存储在线程私有区,所有的对象都存储在共享堆中。如果在在某个方法中的对象不会逃逸出该方法(不被非局部变量引用到,不被其它线程获得),那么他就是线程安全的,哪怕将这个对象作为参数传给其他方法,只要别的线程获取不到这个对象(尽量不要与实例变量打交道),那它就是线程安全的。
举个例子:
1 | public void someMethod(){ |
2 | |
3 | LocalObject localObject = new LocalObject(); |
4 | |
5 | localObject.callMethod(); |
6 | method2(localObject); |
7 | } |
8 | |
9 | public void method2(LocalObject localObject){ |
10 | localObject.setValue("value"); |
11 | } |
样例中LocalObject对象没有被方法返回,也没有被传递给someMethod()方法外的对象。每个执行someMethod()的线程都会创建自己的LocalObject对象,并赋值给localObject引用。因此,这里的LocalObject是线程安全的。事实上,整个someMethod()都是线程安全的。即使将LocalObject作为参数传给同一个类的其它方法或其它类的方法时,它仍然是线程安全的。当然,如果LocalObject通过某些方法被传给了别的线程,那它就不再是线程安全的了。
不同的线程虽然访问的同一个方法,
演示个反例:
1 | public class Test{ |
2 | private Object instance; |
3 | |
4 | public void methodA(){ |
5 | Object local; |
6 | local = instance; |
7 | { |
8 | // do sth wit local |
9 | } |
10 | } |
11 | } |
可以看出,它并没有创建自己的对象(资源),而是指向了一个非局部变量(非线程安全的),这样就会存在竞态条件。
对象成员
对象成员作为对象的一部分存储在堆上,如果多个线程同时更新一个对象的同一成员,那么这个代码就不是线程安全的
线程控制逃逸原则
1.它会不会逃逸
2.它会不会指向了其它共享资源
如果一个资源的创建,使用,销毁都在同一个线程内完成,
且永远不会脱离该线程的控制,则该资源的使用就是线程安全的。
即使对象本身线程安全,但如果该对象中包含其他资源(文件,数据库连接),整个应用也许就不再是线程安全的了。比如2个线程都创建了各自的数据库连接(或者指向同一个对象,或其它资源),每个连接自身是线程安全的,但它们所连接到的同一个数据库也许不是线程安全的。
线程安全及不可变性
当多个线程同时访问一个资源,并且其中的一个或多个线程堆这个资源进行了写操作,才会产生竞态条件。
我们可以通过创建不可变的共享对象来保证对象在线程间共享时不会被修改,从而实现线程安全,如下示例:
1 | public class ImutableValue{ |
2 | private int value = 0; |
3 | |
4 | public ImutableValue(int value){ |
5 | this.value = value; |
6 | } |
7 | |
8 | public int getValue(){ |
9 | return value; |
10 | } |
11 | } |
请注意ImmutableValue类的成员变量value是通过构造函数赋值的,并且在类中没有set方法。这意味着一旦ImmutableValue实例被创建,value变量就不能再被修改,这就是不可变性。但你可以通过getValue()方法读取这个变量的值。
译者注:注意,“不变”(Immutable)和“只读”(Read Only)是不同的。当一个变量是“只读”时,变量的值不能直接改变,但是可以在其它变量发生改变的时候发生改变。比如,一个人的出生年月日是“不变”属性,而一个人的年龄便是“只读”属性,但是不是“不变”属性。随着时间的变化,一个人的年龄会随之发生变化,而一个人的出生年月日则不会变化。这就是“不变”和“只读”的区别。(摘自《Java与模式》第34章)
如果你需要对ImmutableValue类的实例进行操作,可以通过得到value变量后创建一个新的实例来实现,下面是一个对value变量进行加法操作的示例:
1 | public class ImmutableValue{ |
2 | private int value = 0; |
3 | |
4 | public ImmutableValue(int value){ |
5 | this.value = value; |
6 | } |
7 | |
8 | public int getValue(){ |
9 | return this.value; |
10 | } |
11 | |
12 | public ImmutableValue add(int valueToAdd){ |
13 | return new ImmutableValue(this.value + valueToAdd); |
14 | } |
15 | } |
请注意add()方法以加法操作的结果作为一个新的ImmutableValue类实例返回,而不是直接对它自己的value变量进行操作。这也是为了维护它的 “不可变性”
Java同步块
Java同步块(synchronized block)用来标记方法或者代码块是异步的。Java同步块用来避免竞争。
Java同步关键字(synchronized)
Java中的同步块用 synchronized标记。同步块在Java中是同步在某个对象上。所有同步在一个对象上的同步块在同时只能被一个线程进入并执行操作。所有其它等待进入该同步块的线程将被阻塞,直到执行该同步块的线程退出。
有四种不同的同步块:
- 实例方法
- 静态方法
- 实例方法内部的同步块
- 静态方法内部的同步块
上述同步块都同步在不同对象上,实际需要哪种同步块视具体情况而定
1.实例方法同步
1 | public synchronized void add(int value){ |
2 | this.count+=value; |
3 | } |
Java实例方法同步是同步在拥有该方法的对象上(同步在某某对象上的意思就是某一个时刻,只能有一个线程访问该方法)。这样,每个实例方法同步都同步在相同的对象上,即该方法所属的实例->也是this。同一时刻只能有一个线程在该对象的实例方法同步块在运行(也就是说即便是一个实例的不同的方法同步块,也不允许两个线程分别运行)。
这也侧面证明了同步是同步在对象上,而对于实例方法同步块而言,它们都是同步在this对象上。
2.静态方法同步
形式和实例方法同步一样
1 | public static synchronized void add(int value){ |
2 | count+=value; |
3 | } |
同样的,这里synchronized关键字告诉Java这个方法是同步的。静态方法的同步指 同步在该方法所在的类对象上(一个类只能有一个类对象),所以同时只允许一个线程执行同一个类中的静态同步方法(TODO:同上,假如有多个同步的静态方法呢?)。
3.代码块同步
有时你不需要整个方法,而是同步方法中的一部分。Java可以对方法的一部分进行同步
1 | public void add(int value){ |
2 | sychronized(this){ |
3 | this.count+=value; |
4 | } |
5 | } |
请注意Java同步块构造器用括号将对象括起来,该对象被称为 “监视器“。在上面的例子使用的是 “this”,即将调用方法本身的实例作为 监视器对象。
一次只有一个线程能够在同步于同一个监视器对象的Java方法内(包含多个方法同步于同一个对象的情况)执行
对比: [method] Vs [code block]
1 | public class MyClass { |
2 | |
3 | public synchronized void log1(String msg1, String msg2){ |
4 | log.writeln(msg1); |
5 | log.writeln(msg2); |
6 | } |
7 | |
8 | public void log2(String msg1, String msg2){ |
9 | synchronized(this){ |
10 | log.writeln(msg1); |
11 | log.writeln(msg2); |
12 | } |
13 | } |
14 | } |
log1和log2都同步在所调用的实例对象上,所以它们在同步的执行效果上是等价的。如果将log2中的监视器改变为其它对象,则两个方法(简化了说的,其实是一个方法和一个代码块)可以被两个线程在同一时刻分别执行。