

为什么要学习regex呢,其实是因为有点想做一些自己的东西,把自己学到的并发和数据结构算法的一些知识运用起来,一来挺有趣,天天写Android有点觉得太重复化了,二来可以巩固自己所学。而regex正是做东西的第一步,涉及到网络上爬取内容来进行分析,用到regex可以事半功倍,它主要就是处理字符串的,当然,平常我们说到的一些邮箱验证,手机验证也是休要用到regex的。
话不多说,这篇文章就是学习过程中的一些笔记,主要来自于Github上一个开源项目,文末也有注明,大家想学的可以自行观看。
首先,什么是正则表达式?
正则表达式是由一组字母和符号组成的特殊文本,它可以用来从文本中找出满足你需要的格式的句子
为了表述方便,我将正则表达式称之为 元字串,的字符串匹配所得的字符串则为 匹配结果, 用来查找匹配结果的字符串称为 靶字符串 。可能你在别的地方没见过这些称呼,这里说明一下,仅仅为了表述清晰简洁,而起的名字,诸位不要有困惑。
基本匹配
正则表达式其实就是在执行搜索时的格式,它由一些字母和数字组合而成(Dan:还有些符号结合起来)
正则表达式是大小写敏感的,”The” 不会匹配 “the”
元字符
正则表达式主要依赖于元字符,元字符不代表它们本身的字面意思,它们都有特殊的含义。正则表达式的核心就是元字符,理解了如何利用元字符进行组合变化,就学会了regex的使用。一些元字符在方括号中的时候有一些特殊的意思,以下是一些元字符的介绍
| Meta character | Description |
|---|---|
| . | 匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之间的字符 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
下面开始逐一对上面的元字符进行介绍:
点运算符 .
. 匹配任意单个字符,但不匹配换行符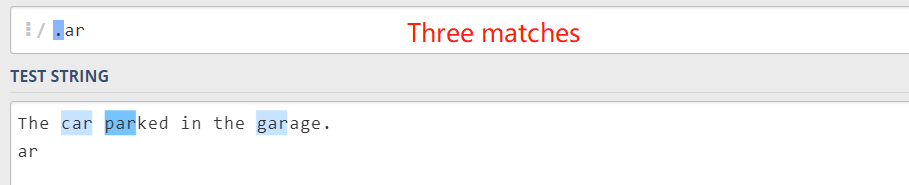
可以思考一个问题,如何才能匹配到换行符呢?
字符集
字符集也叫做字符类。其结构是一对方括号以及其中包含的字符集合,如下
1 | [abtdpo]th |
2 | |
3 | ----------------- 匹配如下 -------------------------- |
4 | ath / bth / tth / dth / pth / oth / |
也可以用连字符来表示一个范围,且它可以和普通字符结合,如下
1 | [b-faqp]th |
2 | |
3 | ------------------ 匹配如下 ------------------------- |
4 | 上面的字符集表示b-f这个范围的字符以及a、q、p这三个字符所以匹配如下字符串 |
5 | bth / cth / dth / eth / fth / ath / qth / pth |
注意,a-c也可以是 1-8 或者 . ,在字符集里的东西都是字符。不过需要注意的是, c-a 是Illegal的,这个也很容易理解哈,从小到大。
否定字符集:
一般来说, “^” 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。例如
[^c]ar 字符集表示的字符则是除了C以外的任何字符,其实也很容易理解啦。
无论什么形式的字符集,它能且仅能表示一个字符
重复次数
后面跟着元字符 +,’*’ or ? 的,用来指定匹配子模式的次数。 这些元字符在不同的情况下有着不同的意思。
1. * 号
表示前置字符重复大于等于0次 ,例如 ‘ a* ‘ 表示多个a开头的字符.
现在假设我们需要匹配 以0个或多个空格开头的cat字符串:
1 | \s*cat |
2. +号
和 * 基本一致,但是匹配次数 >=1, 不同于 * 的 >=0 , 很好理解,例如 \scat可以匹配 a*cat**a ,但是 \s+cat则无法匹配其中的cat,并需要有前置空格才行
3. ?号
实际上,? 属不属于描述重复次数的比较有争议,他表示它的前置字符是可选的,也就是出现0次或者1次。我们姑且理解为重复0次或一次。
例如:表达式 [T]?he 匹配 The 或者 he
{}号
{} 是一个量词,常用来一个或一组字符可以重复出现的次数。常用一个或一组字符可以重复的次数。例如表达
[0-9]{2,4} 匹配最少2位最多4位 0~9 的数字 ,更具体地来说,比如可以匹配 34 345 等等
半闭形态:
[0-9]{2,} => 匹配至少2位 0-9 的字符,不设上限
固定形态:
[0-9]{2 } => 匹配3位0-9的数字
(…) 特征标群
特征标群是一组写在 (…) 中的子模式。其实它就是表示了一个组合,比如 “ab*“ 匹配a后面接一个重复了>=0次的b字符 ,但是 (ab)* 则表示 ab 一起重复了 >=0 次。这样就很容易理解吧,它将其中的子模式和外面的东西隔开,它是完整的,concreat的
再例如:
1 | (c|g|p)ar |
2 | ----------- 匹配 ---------- |
3 | car par gar |
| 或运算符
需要注意的是, | 表示匹配完全的左边和完全的右边(在没有其它元字符的情况下),例如
abc|egfd 可以匹配的是 abc 或者 egfd ,而不是 abcgfd 或者 abegfd,这点需要注意哈,容易搞混淆
但是在有其他元字符的情况下,则不是这样,你只需要注意元字符是不能用来进行匹配的(除非使用转义字符),这点不仅是对于
| , 对其他的元字符也是这样。例如
(T|h)he|car 则匹配
- (T|h)he
- The
- hhe
- car
转码特殊字符
反斜杠 \ 在表达式中用于转码紧跟其后的字符。用于指定 {} [] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \
例如 “ . “ 是用来匹配除换行符外的所有字符的。如果想要匹配句子中的 “ . “ ,则要写成 \.
1 | (f|c|m)at\.? The fat cat sat on the mat. |
2 | --------- 注意?为选择性匹配 -------------------- |
3 | fat / cat / mat. |
锚点
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。 “^” 指定开头, “$” 指定结尾。
^ 和 $ 都需要注意的是,如果不加他们,就是正常地匹配就行了,但是加了他们,那就判断一下,匹配结果是否是位于匹配结果所在字符串的开头或是结尾,是的话才算匹配成功。
1. ^ 号
^ 用来检查 “元字串” 是否在所需匹配字符串的开头,也就是说,如果是的话,那么匹配结果就是这个开头的字符串(注意,不是以它开头的整个字符串哈)
请注意,和 | 一样,它的结合性是很强的,能结合它后面所有的字符,你也可以将它包含在一个特征标群内,作为一个子模式,可以更好地扩展。
需要注意,在遇到元字符的时候,它就会被截断哈,例如
1 | (T|t)he[a-c] |
2 | ------------- 匹配 -------------- |
3 | Thea car is parked in thea garage. |
4 | |
5 | 匹配结果为 thea,很好理解吧,以 (T|t)he 开头的字符串 加上 [a-c] 中的一个字符 |
2. $ 号
同理于 ^ 号, (sub_express)$ 号用来匹配sub_express,并在结果中以是否位于所在字符串尾端来进行筛选 。例如
1 | (at\.)$ => The fat cat. sat. on the mat. |
2 | ---------- 匹配结果 --------- |
3 | mat. 中的 at. ,前面的 at. 都不算 |
其实,有可能你会问,cat. 里面的 at. 为什么没匹配上?你要理解字符串的含义,什么是完整的一个字符串,即便中间有空格,有换行,就是好多个字符串了么?不是滴。
简写字符集
正则表达式提供一些常见的字符集的简写,简化我们的书写内容。简写字符集其本质也是一个字符集,只是在形式上简化了,表格中也指出了他们具体等价的字符集
| Shorthand | Description |
|---|---|
| . | Any character except new line |
| \w | Matches alphanumeric characters: [a-zA-Z0-9_] |
| \W | Matches non-alphanumeric characters: [^\w] |
| \d | Matches digit: [0-9] |
| \D | Matches non-digit: [^\d] |
| \s | Matches whitespace character: [\t\n\f\r\p{Z}] |
| \S | Matches non-whitespace character: [^\s] |
零宽度断言
断言 (assertion) 是一个编程术语。是一种放在程序中的一阶逻辑(入一个结果为真或是假的逻辑判断式)。目的是为了标示与验证程序开发者预期的结果 - 当程序运行到断言的位置时,对应的断言应该为真,若断言不为真,则程序会终止,并给出错误的消息
例如:
1 | x = 5; |
2 | assert x < 4; //assertion |
3 | x = x + 3; |
4 | assert x > 7; //assertion |
Java中默认是禁用断言的,需要配置虚拟器参数,才可以
回到正题,在正则中,先行断言和后发断言都属于非捕获族(不捕获文本,也不针对组合进行计数)。
先行断言用于判断匹配结果是否在另一个确定的格式之前,匹配结果不包含该确定格式(仅作为约束)
| Symbol | Description |
|---|---|
| ?= | 正先行断言 - 存在 |
| ?! | 负先行断言 - 排除 |
| ?<= | 正后发断言 - 存在 |
| ?<! | 负后发断言 - 排除 |
标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。这些标志可以任意的组合使用,它也是整个正则表达式的一部分。
| Flag | Description |
|---|---|
| i | Case insensitive: Sets matching to be case-insensitive. |
| g | Global Search: Search for a pattern throughout the input string. |
| m | Multiline: Anchor meta character works on each line. |
特地说下全局搜索,之前在做test的时候,都是全局匹配,还以为默认就是全局匹配,刚刚返回去看之前的test case,原来后面有个 set options 选项,里面默认是勾选了 g 的。如果不使用全局搜索,默认是返回第一个 匹配结果。
对于多行修饰符来说,我们看一下下面这个例子就明白了
1 | "/.at(.)?$/" => The fat |
2 | cat sat |
3 | on the mat. |
4 | |
5 | ----------------- 匹配结果 ------------------ |
6 | mat. |
7 | |
8 | |
9 | "/.at(.)?$/gm" => The fat |
10 | cat sat |
11 | on the mat. |
12 | |
13 | ----------------- 匹配结果 ------------------ |
14 | fat |
15 | sat |
16 | mat. |
贪婪与惰性匹配(Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串.我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式
所谓贪婪与惰性,实际上就是说当出现多个匹配结果的时候, 贪婪策略会选择那个最长的,而惰性则是选择第一个结果(TODO:还是说最短的,有待验证一下)
贪婪:
1 | "/(.*/at)/" => The fat cat sat on the mat. |
2 | |
3 | --------------- 匹配结果 ------------------ |
4 | The fat cat sat on the mat |
非贪婪
1 | "/(.\*?at)/" => The fat cat sat on the mat. |
2 | |
3 | --------------- 匹配结果 ----------------- |
4 | The fat |
额外地, 思考一下,为什么 “ .* “ 能够匹配任意字符串?
别人告诉我这就是语法,我也很无奈啊,毕竟从两个元字符的语义来讲,是错误的,姑且先这么认为吧.嘿嘿
下面这段话是关于匹配任意字符串的讨论
阿温先森_Gemini:
对
阿温先森_Gemini:
不过这个要去看正则的规范了
阿温先森_Gemini:
其实没啥好说的……最好直接看状态机的定义
我:
比如abc|de
我:
得到的结果是abc或者de
我:
不是abde或者abce
阿温先森_Gemini:
https://www.cs.drexel.edu/~kschmidt/CS360/Lectures/RegularLanguages/regex.pdf
我:
嗯这个问题先放一下,温哥早点休息
我:
我抽时间再看看你说的规约
如果您在阅读本文的过程中存在任何疑问,请通过留言或者信箱联系我,我会尽快回复.